2. Математические методы
а) Методы выделения тренда. Анализ значимости
тренда. Выделение остатков и их анализ.
Одним из важнейших понятий технического анализа является понятие тренда. Слово тренд — калька с английского trend (тенденция). Однако точного определения тренда в техническом анализе не дается. И это не случайно. Дело в том, что тренд или тенденция временного ряда — это несколько условное понятие. Под трендом понимают закономерную, неслучайную составляющую временного ряда (обычно монотонную, т.е. либо возрастающую, либо убывающую), которая может быть вычислена по вполне определенному однозначному правилу. Тренд реального временного ряда часто связан с действием природных (например, физических) законов или каких-либо других объективных закономерностей. Однако, вообще говоря, нельзя однозначно разделить случайный процесс или временной ряд на регулярную часть (тренд) и колебательную часть (остаток). Поэтому обычно предполагают, что тренд — это некоторая функция или кривая достаточно простого вида (линейная, квадратичная и т.п.), описывающая «среднее поведение» ряда или процесса. Если оказывается, что выделение такого тренда упрощает исследование, то предположение о выбранной форме тренда считается допустимым. B техническом анализе обычно предполагается, что тренд линеен (и его график — прямая линия) или кусочно линеен (и тогда его график — ломаная линия).
Предположим, что реализация временного ряда в моменты времени Т=t1, t2,...tN принимает значения X=x1,х2,...xN. Линейный тренд имеет уравнение x=at+b. Известны специальные методы нахождения коэффициентов а и b этого уравнения. В том техническом анализе, который описывается в большинстве книг, тренд находится некоторыми графическими или несложными приближенными приемами. Однако в современной практике широко используются компьютеры, которые за считанные секунды могут по заданному массиву данных выписать точное уравнения тренда заданного вида (в частности, линейного тренда).
Для временного ряда общее уравнение линейного тренда имеет вид:
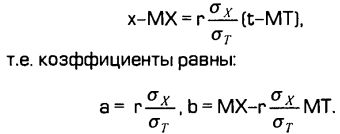
Величина МТ — среднее значение моментов времени t1, t2,...tN. Выбирая подходящую единицу времени, мы всегда можем считать, что t1, t2... — это просто натуральные числа 1,2.... Например, так будет для ценового ряда, в котором цены на акции фиксируется ежедневно на момент начала торгов, если за единицу времени взять один день. В таком случае:
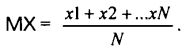
Величины от и о называются средними квадратичными отклонениями, они характеризуют разброс значений вокруг средних значений МТ и MX величин Т и X соответственно. Вычисление о вручную довольно утомительно, особенно для больших массивов данных. Однако все компьютерные программы, ориентированные на финансовые приложения, и даже такие универсальные программы, как Excel (не говоря уж о специальных статистических пакетах, таких как SPSS, Statistica, Statgraphics и др.) дают возможность мгновенно вычислить о для любого массива данных, который введен в память компьютера (и записан в некоторой определенной форме). Что касается величины от, то для случая ряда
натуральных чисел она равна:
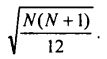
Величина г играет в формуле тренда ключевую роль. Она называется коэффициентом корреляции (другое название: нормированный коэффициент корреляции) и характеризует степень взаимосвязи переменных Х и Т. Коэффициент корреляции принимает значения в промежутке от — 1 до +1. Если он близок к нулю, то это значит, что нет возможности выделить значимый линейный тренд. Если он положителен, то есть тенденция роста изучаемого индекса, причем, чем ближе г к единице, тем эта тенденция становится все более определенной. При отрицательном г имеем тенденцию к убыванию.
Вычисление г весьма громоздко, но современный компьютер делает это практически мгновенно.
При r>0 говорят о положительном тренде (с течением времени значения временного ряда имеет тенденцию возрастать), при r<0 — об отрицательном (тенденция убывания). При г, близких к нулю, иногда говорят о боковом тренде (его еще называют флэт — от английского flat — плоский). В техническом анализе говорят соответственно о бычьем тренде, медвежьем тренде, названия эти были впервые введены на Лондонской фондовой бирже и связаны, по-видимому, с тем, что при охоте медведь наносит удары сверху вниз, а бык при атаке подкидывает врага рогами снизу вверх.

После вычисления линейного тренда нужно выяснить, насколько он значим. Это делается с помощью анализа коэффициента корреляции. Дело в том, что отличие коэффициента корреляции от нуля и тем самым наличие тренда (положительного или отрицательного) может оказаться случайным, связанным со спецификой рассматриваемого отрезка временного ряда. Иначе говоря, при анализе другого набора экспериментальных данных (для того же временного ряда) может оказаться, что полученная при этом оценка величины г намного ближе к нулю, чем исходная (и, возможно, даже имеет другой знак), и говорить о реальном, выраженном тренде тут уже становится трудно.
Для проверки значимости тренда в математической статистике разработаны специальные методики. Одна из них основана на проверке равенства г = 0 с помощью распределения Стьюдента (Стьюдент — это псевдоним английского статистика У.Госсета).
Предположим, что имеется набор экспериментальных данных — значения х1, х2,...xN временного ряда в равноотстоящие моменты времени t1, t2...tN. С помощью специальных программ (см. выше) по этим данным можно вычислить приближение г* к точному значению г коэффициента корреляции (это приближение называют оценкой). Назовем это значение г* экспериментальным. Общая идея метода статистической проверки гипотез такова. Выдвигается некоторая гипотеза, в нашем случае это гипотеза о равенстве нулю коэффициента корреляции. Далее, задается некоторый уровень вероятности а. Смысл этой величины заключается в том, что она является вероятностной мерой допустимой ошибки. А именно, мы допускаем, что сделанный нами вывод о справедливости или несправедливости гипотезы на основании заданного массива экспериментальных данных может оказаться ошибочным, ибо абсолютно точного вывода на основании лишь частичной информации ожидать, конечно, не стоит. Однако мы можем потребовать, чтобы вероятность этой ошибки не превосходила некоторой заранее выбранной величины а (уровня вероятности). Обычно берут ее значение равным 0.05 (т.е. 5%) или 0.10, иногда прут и 0.01. Событие, вероятность которого меньше, чем а, считается настолько редким, что мы берем на себя смелость им пренебрегать. Для временных рядов разной природы эту величину выбирают по-разному. Если речь идет о ряде цен на акции какой-то небольшой фирмы, то риск ошибиться не несет катастрофических последствий (для независимых от этой фирмы участников торгов) и потому а можно взять не очень маленьким. Если же речь идет о крупной сделке, то последствия ошибки могут быть очень тяжелыми и значение а берут поменьше.
Далее рассматриваем следующую величину:
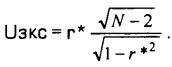
Можно доказать, что при достаточно больших значениях N эта величина Uэкс (тоже являющаяся случайной) очень похожа на одну из стандартных случайных величин, используемых в математической статистике или, как говорят в математической статистике, близка к распределению Стьюдента с числом степеней свободы k (так называется параметр, задающий распределение Стьюдента), равным N-2, где N-число экспериментальных данных.
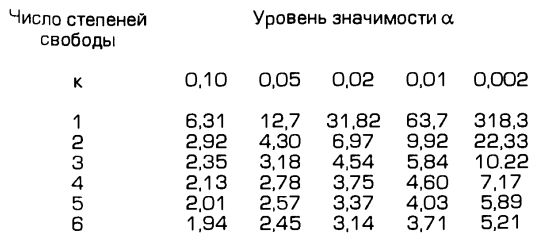
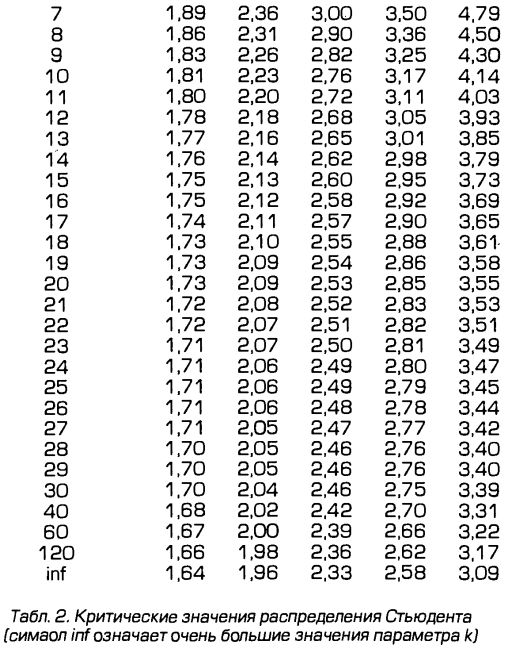
Для распределения Стьюдента имеются подробные таблицы, в которых для заданного уровня вероятности а и числа степеней свободы k указывается критическое значение Икр. Критическим или граничным оно называется потому, что ограничивает двустороннюю (учитывающую и положительные и отрицательные значения) область, вне которой значения случайной величины могут оказаться достаточно редко, с вероятностью не большей, чем а. Точнее, при условии г = 0 имеет место равенство:

В настоящее время значение Uкр можно находить не только из таблиц (где оно приводится только лишь для некоторых отдельных значений уровня вероятности — см. Табл. 2 ниже). Любая современная статистическая программа для компьютера дает возможность мгновенно вычислить Uкр для произвольного заданного уровня вероятности. Как нетрудно понять, с ростом величины а значения Uкр тоже растут.
Далее рассуждают следующим образом. Предположим, что число N достаточно велико. Тогда случайная величина 0зкс распределена приблизительно по закону Стьюдента. Если г = 0, то с большой (т.е. близкой к 1) вероятностью, равной 1 — а, значение Uэкс должно по модулю не превосходить Uкр, т.е. лежать между — кр и Uкр. А вот выходить за пределы отрезка [-Uкр, Uкр] величина Uзкс может только с вероятностью а (которую мы согласились считать малой). Поэтому если I Uзкс I > Uкр, то делают заключение о том, что гипотеза г = 0 экспериментальными данными не подтверждается, т.е. г значимо отличен от нуля и потому тренд является выраженным. Вероятность ошибки такого заключения не превосходит заданного уровня вероятности а. Если же | Uзкс | < Uкр, то говорят, что на заданном уровне вероятности б отвергнуть гипотезу г = 0 нет оснований. В этом случае мы не имеем оснований говорить о выраженном тренде, а тем более использовать рост или убывание этого тренда при прогнозировании динамики временного ряда на будущее.
Например, пусть г*= 0.20 и N= 20. Тогда вычисление дает Uэкс = 0.87. Для уровня вероятности 5% находим из таблицы распределения Стьюдента Uкр = 2.10. Сравнивая Uэкс и Uкр, видим, что тут гипотезу о равенстве нулю коэффициента корреляции отвергать нет основания. Тренд здесь не является выраженным.
Если в результате исследования выяснилось, что тренд является выраженным, то только тогда можно этот тренд использовать для прогнозирования временного ряда. Вычислив коэффициенты а и b уравнения линейного тренда, указанные выше, получаем линейную зависимость, которая на некотором промежутке времени приблизительно описывает тенденцию динамики временного ряда. Графиком является прямая линия, продолжив которую в будущее, мы можем делать предположения о том, каковы будут значения временного ряда в будущем. Однако тенденции имеют свойства меняться, поэтому в какой-то момент времени в поведении временного ряда наступает перелом, после которого старое уравнение тренда уже не может описывать адекватно временной ряд. Сложность заключается в том, что уловить этот переломный момент очень непросто. Исследование линейного тренда ничего не говорит о наличии в будущем точек поворота, так что при их поиске приходится использовать совсем другие методы. О некоторых из них будет сказано ниже.
Кроме линейного тренда, приходится рассматривать и тренды более сложной структуры. В техническом анализе в таких случаях говорят о замедлении или ускорении линейного тренда, как бы признавая, что он утратил свою линейность. При этом заранее указать ту функцию, с помощью которой можно описать этот тренд, обычно не представляется реальным. Поэтому часто на практике просто перебирают несколько простых функциональных зависимостей (которые могут содержать несколько параметров) и для каждой из них оценивают, насколько успешно функцией того или иного вида можно описать тенденцию рассматриваемого временного ряда. При наличии компьютера эти вычисления не занимают много времени, а иногда могут проводиться даже в автоматическом режиме, выделяющем среди нескольких заданных видов трендов оптимальный. Однако далеко не всегда среди рассмотренных функций есть та, которая действительно достаточно эффективно описывает тенденцию развития заданного временного ряда. В этом случае приходится идти другими путями. Так, часто в подобной ситуации производят различные преобразования членов временного ряда (логарифмирование, «дифференцирование» — образование разностей соседних членов ряда, «интегрирование» — суммирование последовательных членов ряда и др.) для того, чтобы попытаться получить временной ряд с ясно выраженным линейным трендом. Если это удается, то к полученному ряду применяют методы вычисления тренда, описанные выше, а потом обратным преобразованием возвращаются к исходному ряду.
б) Методы выявления скрытых зависимостей.
Корреляционный анализ временных рядов.
Спектральный анализ и его применения.
После того, как выявлен тренд, остается задача описать те колебания, которые временной ряд совершает вокруг этого тренда. Ведь ясно, что тренд — это просто тенденция, на ней основывать прогнозы рискованно, так как в разные промежутки времени реальная ситуация может отклоняться, причем весьма значительно, от тренда в ту или иную сторону. При этом отклонение в одну сторону может принести прибыль, а в другую — убытки. В техническом анализе в этом случае говорят об осцилляторах. Методика анализа осцилляторов до самого недавнего времени находилась на очень низком, практически на доматематическом уровне. Только в последние годы с приходом вычислительной техники и специалистов, имеющих хорошее математическое образование (они до сих пор реализовывали его в оборонной промышленности, которая во всем мире сейчас находится в упадке) при анализе осцилляторов стали использоваться достаточно современные методы (основанные на гармоническом и спектральном анализе).
Колебания вокруг тренда разделяют на регулярные (являющиеся комбинацией нескольких синусоидальных или близких к ним колебаний, имеющих разные частоты) и случайные. Для выделения регулярных колебаний (их еще иногда называют скрытыми закономерностями) в математике по "заказам" большого числа прикладных наук разработано множество разных методов. Даже просто перечислить их нет никакой возможности. Однако все эти методы принадлежат обычно к одной из двух больших групп.
В первой группе — методы, своим происхождением обязанные математической статистике, а точнее — теории корреляции. Теория корреляции изучает связи между случайными величинами, а также связи между отдельными значениями временных рядов, разделенных определенным промежутком времени (лагом). Если оказывается, например, что имеется тесная связь между значениями временного ряда, разделенными промежутком времени в 12 единиц, то это можно рассматривать как указание на то, что мы обнаружили колебательную компоненту (не обязательно точно синусоидальную) с периодом в 12 единиц времени. Практически такой анализ производят с помощью специальных программ, которые производят вычисление кореллограммы — оценки для функции корреляции (которая описывает корреляцию между значениями временного ряда, взятыми через всевозможные интервалы времени — лаги).
Вторая группа методов пришла из техники — там при анализе сигналов давно и с успехом используется спектральный анализ. С помощью специальных методов (разложения в тригонометрические ряды и интегралы Фурье) производится выделение наиболее значимых гармоник, которые и дают регулярную часть колебаний вокруг тренда. Здесь вычисления еще более громоздкие, чем в корреляционном анализе. однако ныне об этих сложностях можно совершенно забыть (компьютер производит все необходимые расчеты за несколько секунд). Поэтому настало время учиться анализировать те данные, которые предоставляет спектральный анализ и строить на основании этих данных прогнозы. Эти методы довольно чувствительны к погрешностям в задании исходных данных и потому иногда приводят к заключениям о наличии закономерностей в изучаемом процессе, которых на самом деле нет.
в) Стохастическое прогнозирование (модели ARIMA).
Стохастическое прогнозирование — построение прогнозов на основе разного рода стохастических моделей. Стохастическим модели — это такие модели, которые сконструированы с помощью понятий и методов теории случайных процессов. В частности, среди этих моделей имеются те, в которых будущие значения вычисляются с помощью формул, выражающих эти значения через несколько предыдущих (т.е. соответствующих предшествующим моментам времени) значений. Такого рода модели называют авторегрессионными. Есть модели и другого рода — в них процесс моделируется комбинацией нескольких абсолютно случайных процессов (называемых белым шумом). Эти модели называют моделями скользящего среднего. Понятие скользящего среднего в техническом анализе является одним из основных инструментов, Огромное число прогностических методик основано на различных комбинациях скользящих средних разных порядков' (соответствующих разным временным отрезкам — 7, 14 дней и др.). В инженерной практике сходный метод называется фи-' льтрацией сигнала. Наиболее эффективные модели используют оба указанных метода. Одна из самых распространенных. комбинированных моделей такого рода — это ARIMA. По-русски это звучит, как АРПСС и расшифровывается как Авто-Регрессия и Проинтегрированное Скользящее Среднее. Мы не будем здесь входить в подробности построения этих моделей — они достаточно сложны. Для тех, кто хочет всерьез ознакомиться с этим, самым эффективным классом стохастических моделей, рекомендуем обратиться к книге "Статистический анализ данных на компьютере" [11]. Непосредственные вычисления в ARIAL производятся только с применением компьютера, так как они очень громоздки. Метод ARIMA является наиболее распространенным общим методом стохастического моделирования во многих областях, в том числе и при серьезном подходе к анализу данных и прогнозированию финансовой деятельности.
После построения стохастической модели ее можно использовать для прогнозирования. Однако следует отметить, что прогноз в этой (как и во всех других математических моделях) выдается с указанными границами, в пределах которых возможна ошибка.

На приведенной диаграмме (она построена с помощью программы Statgraphics) указан прогноз, получаемый с помощью стохастической модели. Он состоит из основной линии и двух граничных, между которыми с заданной степенью уверенности (называемой доверительной вероятностью, она обычно равна 95%) будут находиться члены исследуемого временного ряда (например, ряда цен) в ближайшем будущем.
г) Использование чисел Фибоначчи. Методы Ганна.
Использование чисел Фибоначчи в техническом анализе имеет довольно давнюю историю. Сами зти числа были введены математиком Леонардо Пизанским (его называли
Фибоначчи, — т.е. сын Боначчо, а Боначчо — добродушный -
было прозвищем его отца) в его "Книге абака" в 1228 году, где он их использовал для вычисления роста потомства у Кроликов. На самом деле этот ряд чисел был известен еще в древнем Египте. В книге Фибоначчи приведены первые 14 чисел этого бесконечного ряда чисел.
Каждое число в этой последовательности равно сумме двух предыдущих. Первыми двумя числами берутся 1 и 1, а се последующие однозначно определяются с помощью указанного выше правила. Числа Фибоначчи особенно хорошо известны в развлекательной части математики, а также в некоторых разделах современной математики (издается даже международный математический журнал Fibonacci Quarterly, посвященный числам Фибоначчи и их применениям). Можно доказать, что отношение каждого числа Фибоначчи к последующему с ростом порядкового номера этого числа стремится к числу 0.618... — к знаменитому числу золотого сечения. Это число пользовалось огромной популярностью еще в средние века, а сейчас ему придается чуть ли не фундаментальное значение во многих областях искусства и науки. Однако очень часто на самом деле оказывается, что важную роль играет не само это число, а близкое к нему число 2/3 = 0.666666... Число 2/3 действительно фундаментально, оно символизирует троичное деление, а вот число золотого сечения часто используется просто "для красоты".
В техническом анализе есть несколько методов, которые связаны с использованием числа золотого сечения и нескольких производных от него чисел. Прежде всего можно отметить, что продолжительности отдельных элементов (волн) в волновой теории Р.Эллиотта (о которой будет рассказано ниже) связываются между собой именно с помощью этого числа. Кстати, само разделение цикла на 8=5+3 этапов в волновой теории указывает на числа Фибоначчи 3,5,8.
В техническом анализе для делений (вертикальными и наклонными прямыми) чарта используют число 0.618... и производные от него числа (например (0.61 8...] = 1-0.61 8...= 0382...). Например, строится сетка, соотношение сторон которой равно числу золотого сечения или отношению чисел Фибоначчи (что, как мы уже знаем, примерно одно и то же). Относительно этой сетки и изучаются отдельные элементы чарта (линии сопротивления и поддержки, точки поворота и другие характерные точки). Вертикальные линии этой сетки задают периоды Фибоначчи (причем в литературе рекомендуется игнорировать первые две-три линии этого разбиения). Можно также строить отдельные наклонные линии, тоже задаваемые числами Фибоначчи. Эти линии проводятся от ключевых точек графика (например, от точек поворота). Считается, что линии Фибоначчи сохраняют свое действие некоторое время и после изменения тренда, что позволяет использовать эти линии для прогнозирования. Однако во всех этих случаях можно просто использовать число 2/3 и получить ничуть не худшие результаты (хотя, может быть и не столь эффектно оформленные, как при использовании золотого сечения). С помощью таких делений иногда удается весьма эффективно описать движения цен. Однако при резком развороте рынка приходится заново перерисовывать все линии Фибоначчи.
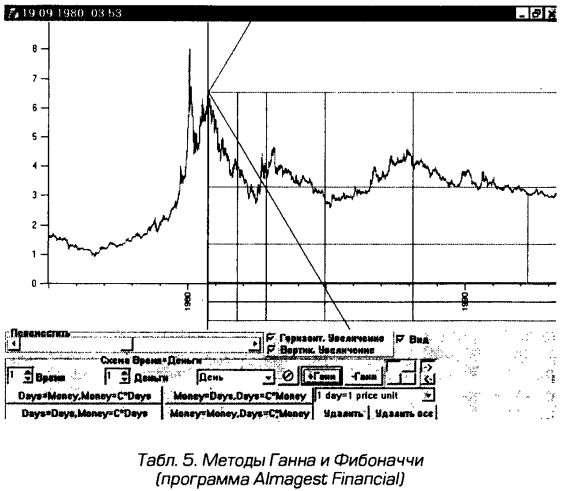
Подробную систему графического анализа чартов разработал Уильям Ганн (1878-1955), который одним из первых стал использовать в техническом анализе геометрические методы. Он строил наклонные линии (линии Ганна), задаваемые числами 1/8, 1/4, 1/3, 3/8, 1/2, 5/8, 2/3, 3/4, 7/8, и использовал их, в частности, для нахождения линий сопротивления и поддержки — фундаментальных линий в графическом техническом анализе. При приближении к этим линиям Ценовой ряд прекращает рост (для линии сопротивления) или падение (для линий поддержки) или, по крайней мере, сильно замедляет их. При некотором желании среди этих чисел можно найти такие, которые приближенно выражаются через число золотого сечения и на этом основании сделать вывод, что это замечательное число и здесь играет основную роль. Однако идея Ганна была намного проще — он просто выписал последовательность тех чисел в отрезке [0,1], которые задаются достаточно простыми дробями.
Ганн строил лучи, исходящие их характерных точек чарта (обычно из точек поворота), чтобы получать линии сопротивления и поддержки. Самое трудное здесь — правильно выбрать исходную точку линий Ганна. Можно комбинировать сетку Фибоначчи и линии Ганна. Эти методы реализованы во многих программах технического анализа (таких, как, например, MetaStock).
|









. Низкие спреды, кэшбек – до 60%, качественная аналитика, бесплатные торговые стратегии и обучающие материалы. Разрешен скальпинг и высокочастотная торговля, любые торговые советники и стратегии. Минимальный депозит – от $10.")
, качественная аналитика и обучение.")


